Text-to-Image (T2I) generative models are widely popular, allowing customization and fine-tuning on small datasets. Light-weighted personalized methods like DreamBooth and LoRA deliver exceptional visual quality, but their outputs are static images, lacking temporal freedom.
The emergence of text-to-video (T2V) models introduces the need for temporal modeling on original T2V models. However, tuning these models on video datasets poses challenges due to the complexities of hyperparameter tuning, personalized video collection, and extensive computational resources.
In AnimateDiff, there’s no need for a personalized T2I model, no model-specific tuning efforts, and no requirement for achieving content consistency over time.
Method:
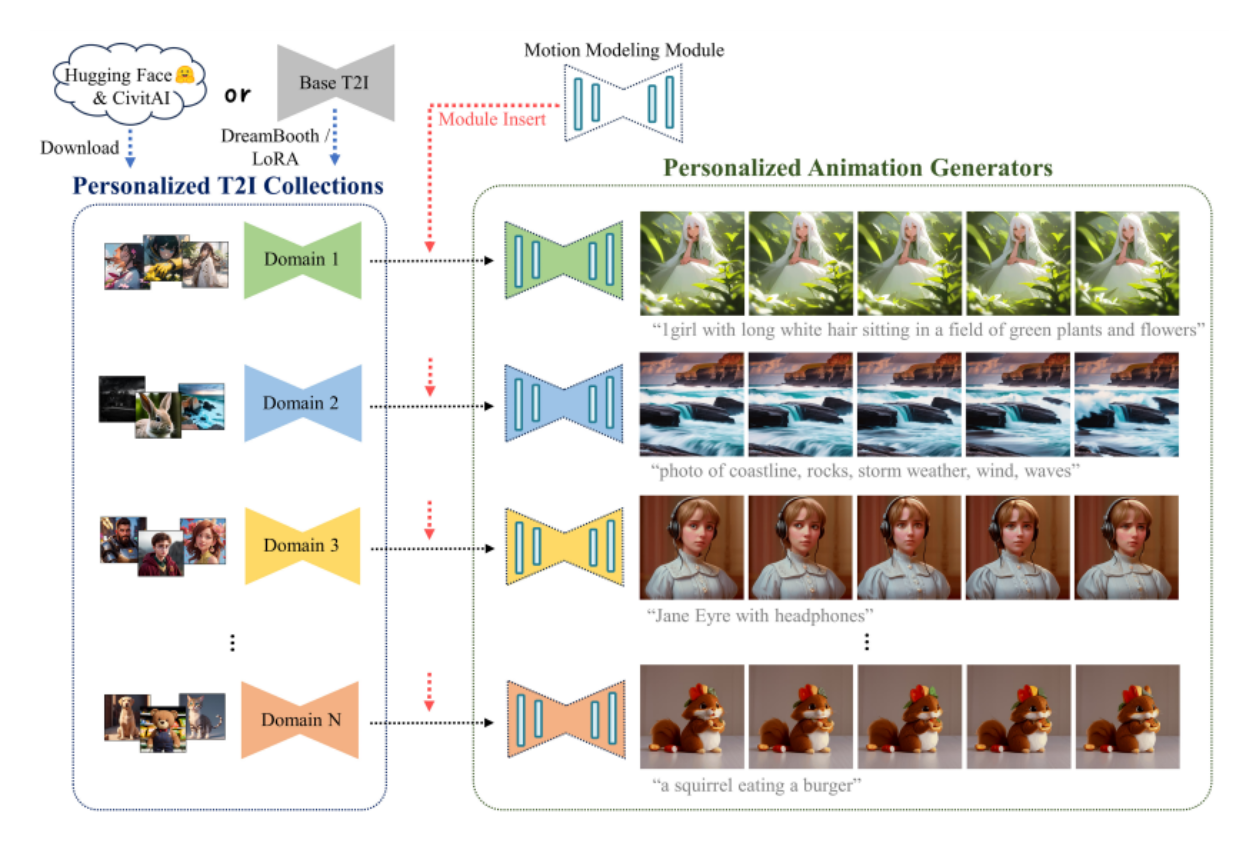
Many T2I models are derived from a common base model (Stable Diffusion). However, collecting videos from every domain is impractical. To address this issue, a motion modeling module is introduced, capable of animating most personalized T2I models without the need for additional data collection or custom training.
- The Motion Modeling module is added to the base model of T2I and fine-tuned on a large dataset of video clips, allowing it to learn reasonable motion priors (patterns or behaviors).
- The parameters of the base T2I model remain unchanged during this process.
- After fine-tuning, the personalized T2I models benefit from the learned motion priors, enabling the generation of smooth and appealing animations for various personalized models.
Generalization:
The motion priors learned from the module can be generalized to different domains such as 3D cartoons and 2D anime. This implies that it can serve as a baseline, providing a starting point or foundation. This facilitates the quick generation of animated outputs.
Challenge of Personalized T2I Models:
Individual users often find it challenging to train personalized models due to the requirements of large-scale data and computational resources, which are typically only accessible to large companies. To address this challenge, several methods have been introduced, including:
- Textual Inversion: Optimizes word embeddings for each concept and freezes the original network during training.
- DreamBooth: Fine-tunes the entire network with a preservation loss as regulation.
- Custom Diffusion: Improves fine-tuning efficiency by updating only a small subset of parameters and allows concept merging through closed-form optimization.
- DreamArtist: Reduces the input to a single image during the personalization process.
- LoRA: Originally designed for language model adaptation, it has been utilized for fine-tuning text-to-image models and achieved good visual quality.
Currently, our focus is specifically on DreamBooth and LoRA because they maintain an unchanged feature space of the base T2I model.
Existing Approaches for T2I Animation
Personalized Image Generation:
- In AnimateDiff, Stable Diffusion is used for Text-to-Image generation.
- Direct fine-tuning without regularization can lead to overfitting or catastrophic forgetting, especially when dealing with a small dataset.
- DreamBooth Approach:
- Utilizes a rare string as an indicator to represent the target domain.
- Augments the dataset by adding images generated by the original T2I model without the indicator.
- Allows the model to learn to associate the rare string with the expected domain during fine-tuning.
- LoRA Approach:
- Attempts to fine-tune the model weights’ residual, (W’ = W + α∆W), providing more control over generated results.
- (∆W) is decomposed into two low-rank matrices, (A) and (B), to reduce overfitting and computational costs.
Personalized Animation:
- Naive Approach:
- Inflate a T2I model by adding temporal-aware structures and learning motion priors from large-scale video datasets.
- Collecting personalized videos for domains is costly, leading to potential knowledge loss for the source domain.
- Proposed Approach:
- Train a generalizable motion modeling module separately.
- Insert the module into any personalized T2I without specific tuning, preserving pre-trained weights.
- Generalizable motion priors learned by the module can be applied to various domains, facilitating a simple and effective baseline for personalized animation.
Motion Modeling Module
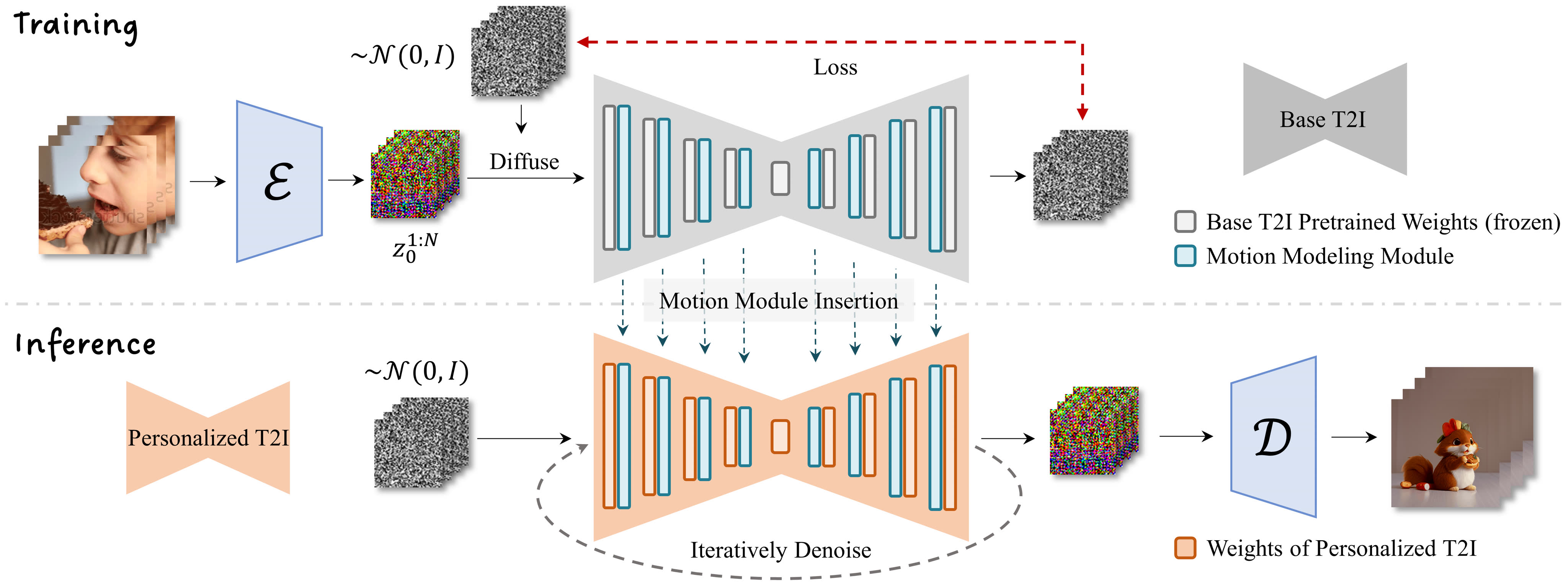
Network Inflation:
The SD model is designed to process image data in batches and is not initially compatible with the motion modeling module (MMM), which requires a 5D video tensor input (batch × channels × frames × width). To address this issue, a new method called Network Inflation Solution is introduced. This solution transforms the original SD model to make it compatible with the MMM.
 Motion Module Design:
Motion Module Design:
The motion module helps exchange information efficiently across frames in animations. It is designed to be sufficient for modeling motion priors.
Vanilla Temporal Transformer:
- It comprises several self-attention blocks operating along the temporal axis.
- When passing through the MMM, the height and width are reshaped to the batch dimension, resulting in a sequence of size batch × height × at the length of frames.
- The reshaped feature map then undergoes self-attention blocks followed by softmax operations.
Training Objective:
The training process of the MMM is similar to the latent diffusion model. During optimization, the pre-trained weights of the base Text-to-Image (T2I) model are frozen to maintain the unchanged feature space.
Implementation Details:
The base model for training the MMM is Stable Diffusion v1, using the WebVid-10M dataset (text-video pairs). Video clips are sampled with a stride of 4, resized, and center-cropped to achieve a resolution of 256 × 256, as experiments show effective generalization to higher resolutions.
The final video length set for training is 16 frames. Using a diffusion schedule slightly different from the original schedule helps achieve better visual quality and avoid artifacts such as low saturability and flickering.
A linear schedule is employed (βstart = 0.00085, βend = 0.012).
Trigger Words in Prompt:
Compared with Text2Video-Zero.
Limitations:
Most failure cases occur when the domain of the personalized T2I model is far from realistic, such as cartoons. In these cases, animation results have apparent artifacts and cannot produce proper motion. The hypothesis suggests this is due to a large distribution gap between training videos (realistic) and personalized models (cartoons, etc.).
A possible solution is to manually collect several videos in the target video domain and slightly fine-tune the MMM.