FreeInit
In the realm of text-to-image generation, diffusion models have exhibited impressive generative capabilities. Building upon the success of text-to-image models, researchers are now exploring the application of diffusion models in text-to-video generation.
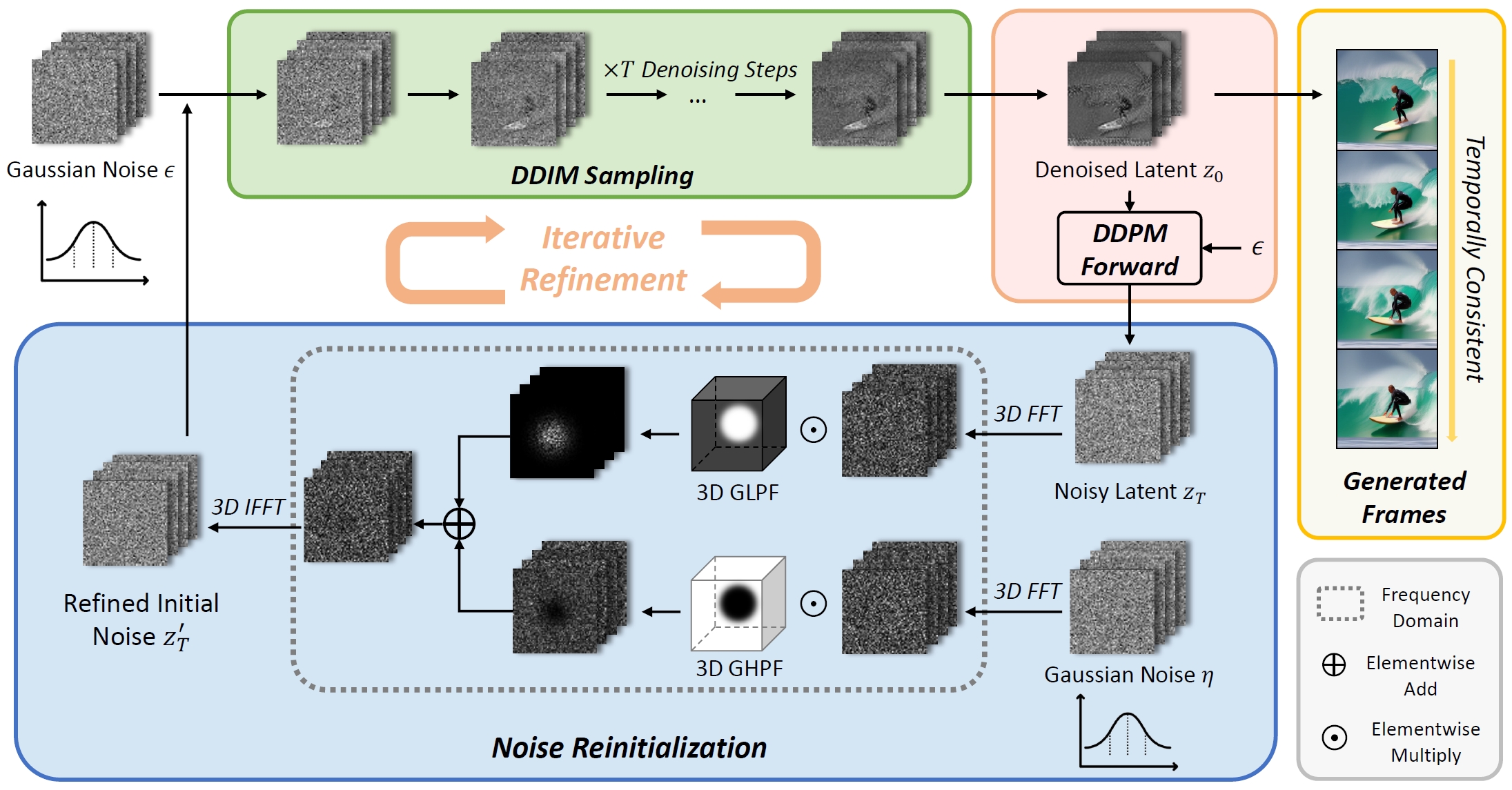
Gap in Diffusion Process:
During training, Gaussian Noise is added and gradually increased in the diffusion process. The video is corrupted gradually, transforming it into noise during this diffusion process.
After obtaining the noise, the diffusion model is trained to predict the noise added in the diffusion process and reconstruct the original clean video from the noise. The model is iteratively trained to denoise the corrupted video (noised video) and attempt to recreate the clear underlying structure.
During inference, the trained model is tasked with generating a new video by iteratively denoising pure Gaussian noise. A notable difference is observed between pure noise and corrupted latents used in training.
In the diffusion process, clean latents are not fully corrupted into pure Gaussian noise. Low-frequency components, such as large-scale patterns, smooth changes, brightness gradients, and colors, are corrupted at a much slower rate compared to high-frequency components, which include fine details, sharp edges, and rapid changes.
Especially during inference, the initial noise introduced, particularly if it is a low-frequency component, significantly impacts the generation quality.

Inference Process:
In the inference process, the method begins by initializing independent Gaussian noise.
The initialized Gaussian noise undergoes a denoising process using DDIM (Denoising Diffusion Implicit Model) to produce a clean video latent.
Then, we denoise the clean video latents using a forward diffusion process to generate a noisy version of video latents.
The noise generated now is improved because it comes from the generated video, providing information about both low-frequency and high-frequency components.
In the reinitialization step, the low-frequency component of noisy latents is separated from high-frequency components. In this reinitialization, we combine the low-frequency components of the improved noise latents with the high-frequency component of random Gaussian noise.
Now, this serves as the starting point for the DDIM sampling process to generate a video frame with enhanced temporal consistency, combining the denoised low-frequency component with the randomness of the high-frequency component and visual appearance.
-
Frequency Domain Operations:
- Transform the noise latent zₜ into the frequency domain using the 3D Fast Fourier Transformation (FFT), denoted as FL zₜ.
- Transform a randomly sampled Gaussian noise η into the frequency domain, denoted as FHη.
-
Frequency Filtering:
- Apply a spatial-temporal Low Pass Filter (LPF), denoted as H, in the frequency domain to both FL zₜ and FHη.
- The filter preserves the low-frequency components of zₜ while allowing randomness in the high-frequency components.
-
Combining Low and High Frequencies:
- Combine the low-frequency components of zₜ (FL zₜ) with the high-frequency components of the random Gaussian noise η (FHη) element-wise.
-
Inverse Frequency Transformation:
- Transform the resulting blended representation Fz’ₜ back from the frequency domain to the time domain using the 3D Inverse Fast Fourier Transformation (IFFT).
-
Reinitialized Noise:
- The outcome is the reinitialized noise z′ₜ, serving as the starting point for new DDIM sampling.
-
Role of Reinitialized Noise:
- This reinitialized noise z’ₜ is used in subsequent iterations of the DDIM sampling process, contributing to the refinement of the initial noise for each iteration.
- The goal is to facilitate the generation of frames with enhanced temporal consistency and visual appearance.

Video Generation Models
GAN-Based Models:
- StyleGAN-V
- MoCoGAN-HD
These models leverage the powerful StyleGAN architecture to generate videos.
Transformer-Based Models:
- Phenaki
- CogVideo
- NUWA
These models encode videos as visual tokens and train transformer models to auto-regressively generate these tokens.
Diffusion-Based Models:
- Video Crafter
- Animatediff
- Model Scope
These models extend diffusion models, which have shown remarkable progress in text-to-image generation, for video generation.
Signal-to-Noise Ratio (SNR):
SNR is a metric used to analyze the progress of information corruption during the generation process. In the UCF-101 dataset analysis, low-frequency components exhibit SNR larger than 0dB, indicating significant information leaks in the low-frequency component of the initial noise. The consistent pattern of higher SNR values in low-frequency components suggests that the diffusion process struggles to fully corrupt information within spatio-temporal low-frequency components of the video latent. Less corrupting information in these components results in implicit leakage of signal information during training.

Framework:
- Initialization: Independent Gaussian noise ϵ is initialized during the inference process.
- DDIM Sampling: ϵ undergoes the DDIM sampling process to yield a primary denoised latent z₀.
- Forward Diffusion Process: The noise latent zₜ is obtained through the forward DDPM diffusion process, where noise is added to diffuse z₀ to zₜ.
- Improving Spatio-Temporal Correlation:
- The low-frequency components of the noise latent zₜ exhibit better spatio-temporal correlation compared to the initially initialized Gaussian noise ϵ.
- Noise Reinitialization Process:
- A noise reinitialization process is performed on zₜ:
- zₜ is transformed into the frequency domain through 3D FFT.
- Spatio-temporal low-frequency components of zₜ are fused with the high-frequency from a randomly sampled Gaussian noise η.
- The result is transformed back to the time domain, yielding a refined initial noise z′ₜ.
- A noise reinitialization process is performed on zₜ:
- Iterative Refinement:
- This refined initial noise z′ₜ is used as the initial noise for the next iteration, leading to an iterative refinement process.
- Mathematical Representation:
- The mathematical representation involves a weighted combination:
- zₜ = (αt)^(1/2)* (z₀+1−*αt)^(1/2)ϵ
- This equation highlights the progressive refinement of z₀ to zₜ, with αₜ aligned with the β schedule used at training, such as the Stable Diffusion schedule.
- The mathematical representation involves a weighted combination:

Evaluation of Diffusion Models: Animatediff, Model Scope, Video Crafter
The evaluation process was applied to three publicly available diffusion models: Animatediff, Model Scope, and Video Crafter. The evaluation was performed on prompts from UCF-101 and MSR-VTT datasets. During inference, the parameters of the frequency filter for each model were kept the same for comparison. A Gaussian Low Pass Filter (GLPF) with a normalized spatio-temporal stop frequency (Do) of 0.25 was utilized.
The default inference settings of each model were first adopted for a single inference pass. Subsequently, four extra FreeInit iterations were applied to refine the initial noise, and the progress of generation quality was evaluated. All FreeInit metrics in quantitative comparisons were computed at the 4th iteration.
Metrics Used:
-
Temporal Consistency:
- To measure temporal consistency, the frame-wise similarity between the first frame and the (N-1) frames is computed. This metric helps assess how consistently the generated video frames follow each other.
-
DINO Metric (Visual Similarity):
- The DINO metric, utilizing ViT-S/16, is employed to measure visual similarities. This metric is averaged across all frames to provide an overall assessment of visual quality.
Evaluation Process:
-
Default Inference:
- Default inference settings of each model are applied for a single inference pass.
-
FreeInit Iterations:
- Four extra FreeInit iterations are performed to refine the initial noise and improve the quality of video generation.
-
Quantitative Comparisons:
- All FreeInit metrics for quantitative comparisons are computed at the 4th iteration, allowing a comprehensive assessment of the models’ performance.
This evaluation process ensures a thorough analysis of the temporal consistency and visual similarity of the generated video frames across the three diffusion models under consideration.